
Cinématique de fonctionnement du serveur batch
Présentation
Le serveur batch intégré au progiciel permet de lancer en arrière plan, sur le serveur d'application :
- des tâches définies dans la table correspondante. Une tâche peut être un traitement standard du progiciel (ie. une fonction dont l'action associée est de type Traitement standard), un script (Unix ou DOS selon le type de serveur sur lequel il est lancé). Un cas particulier de tâche de type traitement est le lancement d'une impression.
- des groupes de tâches. Il s'agit de plusieurs tâches qui s'exécutent en séquence, à condition que la tâche précédente se soit terminée sans erreur.
- des tâches ou des groupes de façon régulière, par le biais d'abonnements.
Le démarrage du serveur batch peut être fait directement depuis le progiciel, mais également par une commande directement depuis le système.
Une tâche de surveillance permet de visualiser les tâches quel que soit leur état (en attente, en cours, terminé), de modifier les paramètres de lancement si elles n'ont pas démarré, de les arrêter lorsqu'elles tournent, ou de visualiser le fichier de trace lorsqu'elles sont terminées.
La soumission de tâches pour exécution via le serveur de batch peut se faire de différentes façons :
- directement via une fonction de soumission de requêtes.
- en créant un abonnement de tâches actif.
- en déposant des fichiers de requête dans un répertoire dédié défini dans les paramètres du serveur batch. Ce type de soumission peut être désactivé globalement, ou réservé à certains utilisateurs en fonction de la valeur du paramètre utilisateur EXTBATCH rattaché au groupe SUP. On trouvera dans l'annexe technique le détail du fonctionnement de ce mode de soumission, qui peut être ainsi réalisé par le biais d'un automate d'exploitation.
Cinématique détaillée
Les schémas ci-dessous décrivent la cinématique de fonctionnement du serveur batch. Les losanges figurent des tests logiques, les boites jaunes des actions simples, les boîtes vertes des actions plus complexes décrites dans un autre schéma. Le titre de chaque schéma est donné dans un carré bleu. Enfin, les boîtes rouges figurent une action terminale.
Le serveur est un processus ADONIX fonctionnant sur un dossier SERVX3 dédié. Il utilise un ensemble de tables se trouvant dans le dossier superviseur (et de ce fait visibles par l'ensemble des dossiers). Un seul processus serveur tourne à un moment donné. Le lancement de la tâche serveur se fait selon le processus suivant :

Une fois les vérifications réalisées et les initialisations faites, des fichiers sont mis en place dans des sous-répertoires du répertoire SERVX3 :
- un fichier run est mis en place dans le sous-répertoire FIL. Ce fichier ne suffit pas à déterminer que le serveur est actif (la tâche pouvant avoir été interrompue brutalement). Une technique de polling est mise en place pour vérifier que le serveur fonctionne toujours. Par contre, le fait que le fichier run ne soit pas là indique que le serveur ne fonctionne pas.
- un fichier serveur.pid, donnant le numéro de processus du serveur, est créé dans le répertoire tmp.
- La trace du serveur est ouverte dans le répertoire TRA du dossier.
Par ailleurs, on vérifie le nombre de requêtes pouvant être lancées simultanément, d'une part en fonction du paramétrage réalisé, et d'autre part en fonction du nombre de processus batch autorisés par la licence.
La boucle principale de fonctionnement du serveur batch est résumée ci-dessous :
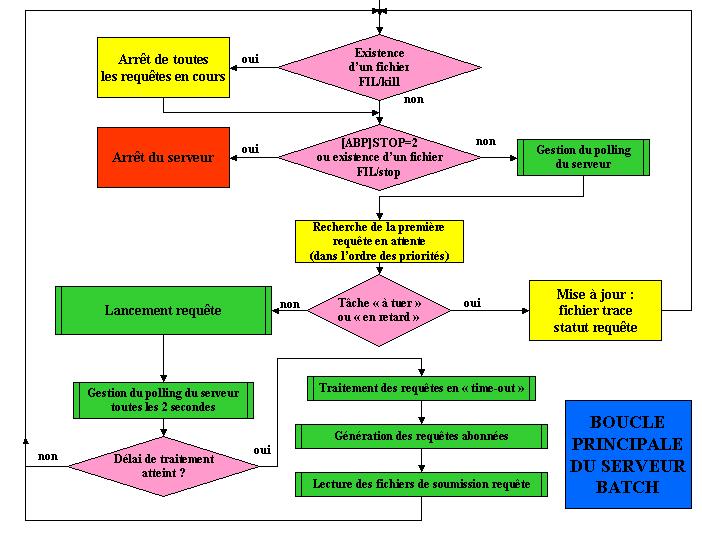
Il est à noter que la présence d'un fichier kill dans le répertoire FIL du dossier SERVX3 provoque l'arrêt de toutes les tâches batch encore en cours, et la présence d'un fichier stop dans ce même répertoire provoque l'arrêt du serveur. Si on veut arrêter le serveur batch en arrêtant toutes les requêtes, il faut placer ces deux fichiers dans le répertoire, en commençant par le premier, mais de façon rapprochée (dans un délai de 2 secondes), afin que le serveur commence par arrêter les tâches, puis s'arrête.
Les tâches à exécuter sont recherchées dans l'ordre chronologique croissant : la plus prioritaire est la plus ancienne, dès lors que le retard admissible au lancement (tel qu'il est défini, en heures, dans la fiche tâche), n'est pas dépassé. Il est à noter à ce propos que les contraintes horaires données par ailleurs définissent une heure de lancement programmée pour la tâche. Cf. le chapitre concernant la >gestion des contraintes horaires ci-après.
Il est à noter qu'un délai « de traitement » permet de définir un délai au bout duquel le serveur s'active périodiquement pour traiter les nouvelles requêtes arrivant (un délai compris entre 30 secondes et une minute est souvent raisonnable, sachant que toutes les 2 secondes s'exécute un traitement de polling répondant aux sollicitations des processus qui interrogent le serveur pour vérifier qu'il est toujours vivant.
Le lancement d'une requête se fait ainsi que le montre le schéma ci-dessous :

Sur le dossier SERVX3, on lance un processus ADONIX sur le bon dossier, et on récupère le numéro de processus pour mettre à jour les informations correspondantes. Si la requête a été soumise par fichier, on met à jour les fichiers correspondants.
Sur le dossier cible, l'exécution du processus associé à la requête commence par ouvrir la trace, vérifier les contraintes d'exécution (est-on en mono-utilisateur, l'utilisateur a-t-il toujours les droits d'exécution ?). Puis on lance le traitement ou le script, et on exécute le traitement de fin de tâche :
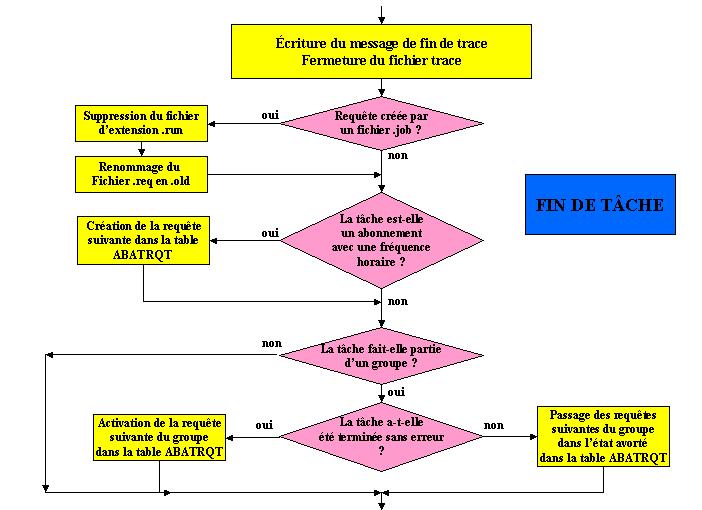
Il est à noter qu'outre la fermeture du fichier de trace et la mise à jour des fichiers relatifs aux lancements par fichier, la fin de tâche active la tâche suivante d'un groupe s'il n'y a pas eu d'erreur, et passe les tâches suivantes dans l'état avorté sinon.
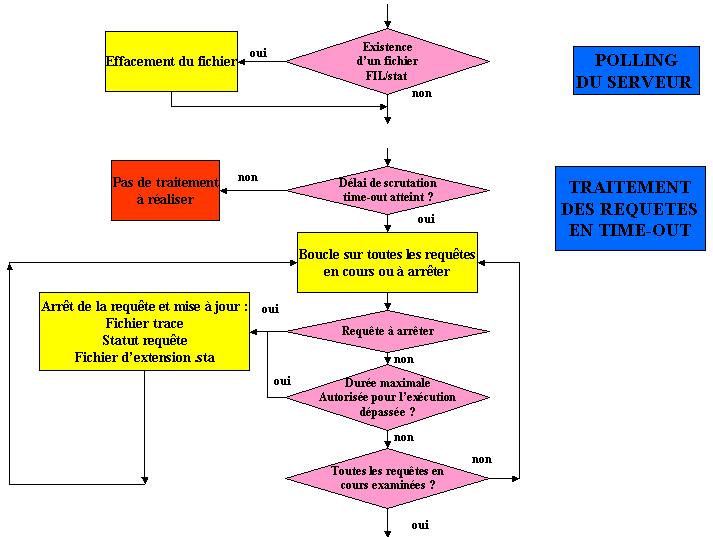
Les traitements complémentaires non décrits ci-dessus concernent tout d'abord le polling (on efface un fichier stat dans le sous-répertoire FIL du dossier SERVX3, s'il a été créé par une tâche désirant tester que le serveur est toujours vivant), et le traitement des requêtes en time-out. Il est à noter qu'un délai plus important que le premier délai de traitement peut être défini pour éviter le test des requêtes pour vérifier si elles ont dépassé le délai imparti. Ce traitement étant lourd, on peut proposer un délai de l'ordre de 5 minutes par exemple (ceci suppose que l'on admette un dépassement d'au plus 5 minutes du délai maximum autorisé pour cette tâche) :
La mise à jour de la liste des requêtes peut être faite par l'intermédiaire de fichiers externes (c'est la boîte lecture des fichiers de soumission de requête indiquée dans la boucle principale du serveur). Ce traitement est décrit par le schéma ci-dessous :

Enfin, le dernier traitement présent dans la boucle d'exécution du serveur concerne le traitement des abonnements. Il est décrit ci-dessous :

Gestion des contraintes horaires
Il est possible de définir des contraintes horaires pour le lancement d'une tâche ou d'un groupe de tâches. Ces contraintes sont considérées uniquement pour le lancement de la tâche. Prenons un exemple :
- une tâche qui ne peut s'exécuter que de 18 heures à 22 heures ne pourra pas être lancée pour s'exécuter à 17 heures (on devra définir 18 heures comme heure de lancement).
- par contre, si par suite de l'exécution d'autres tâches en retard, et du fait d'un nombre limité de tâches simultanées, le serveur batch n'est en mesure de lancer la tâche qu'à 22 heures 30, elle sera tout de même lancée, sauf si on a indiqué qu'un retard de 4 heures ne permettait plus de lancer la tâche en question.
- de même, il est possible d'indiquer un time-out d'exécution de la tâche : ce délai time-out se réfère à l'heure de lancement effective de la tâche : il permet donc de limiter sa durée effective d'exécution.
- ainsi, si la tâche précédente doit impérativement être terminée à 22 heures, et si on sait qu'elle ne soit pas prendre plus d'une heure d'exécution, on admettra 3 heures maximum de retard et 1 heure de time-out. Si cette tâche est programmée à 18 heures, elle sera terminée à 22 heures, ou elle aura été interrompue, ou jamais lancée.
Les contraintes horaires sont définies par une table dédiée commune à tous les dossiers, et permettant de définir des horaires pour les jours ouvrés et des horaires différents pour les jours fériés. Un code de contrainte horaire peut être affecté à une tâche, mais également à un groupe de tâches. Il est important de noter les règles suivantes :
- le contrôle de contrainte horaire d'une tâche lancée directement (par fichier de requête ou par soumission directe) se fait en fonction du code de contrainte horaire qui lui est associé : la tâche ne peut être lancée qu'à la première heure possible si le jour le permet.
- si une tâche fait partie d'un groupe, on ne teste plus ses contraintes horaires propres, mais uniquement celles du groupe (le groupe est lancé conformément au code de contrainte horaire qui s'y trouve, les tâches le composant étant ensuite lancées successivement à l'achèvement de la tâche précédente sans aucun autre contrôle de contrainte horaire).
- si une tâche (ou un groupe de tâches) est déclenché à partir d'un abonnement, la seule contrainte vérifiée est la contrainte liée aux calendriers d'exclusion. En effet, dans ce cas, on donne directement dans l'abonnement une heure (ou une fréquence) d'exécution, et aucun contrôle de contraintes horaires n'est plus fait sur la tâche ou le groupe de tâches figurant sur l'abonnement.
Tables mises en œuvre
Il est à noter que les tables concernées sont toutes situées dans le dossier superviseur, ce dossier pouvant prendre des noms divers selon le produit installé : X3, PAYE, GX par exemple. Elles sont donc communes à tous les dossiers.
Table | Intitulé Table |
ABATABT [ABA] | Serveur batch (abonnements) - en-tête |
ABATABTD [ABD] | Serveur batch (abonnements) - lignes |
ABATCAL [ABC] | Calendrier d'exclusion |
ABATGRP [ABG] | Serveur batch (groupes) |
ABATHOR [ABH] | Contraintes horaires |
ABATPAR [ABP] | Paramètres du serveur batch |
ABATRQT [ABR] | Requêtes du serveur batch |
ABATTAC [ABT] | Serveur batch (tâches) |