
Explanation of batch server operation
Presentation
The batch server integrated in the software is used to launch in batch mode on the application server :
- Tasks defined in the corresponding table. A task can be a standard process in the software (ie. a function whose associated action is of the type Standard process), or a script (Unix or DOS according to the server type on which it is launched). A specific example of a task of the process type is the launch of a print.
- Groups of tasks. This is several tasks that are executed in sequence, on the condition that the previous task is completed without error.
- tasks or groups of tasks that happen regularly, by means of recurring tasks.
The start-up of the batch server can be carried out directly from the software, but also by a command directly from the system.
A surveillance task is used to view the tasks irrespective of their status (pending, in process, terminated), to modify the launch parameters if they have not started, and to stop those which are running, or to view the log file when the tasks are complete.
The submission of tasks for execution via the batch server can be made in different fashions :
- directly via request submission function.
- by creating a recurring task for the active tasks.
- by placing request files in a dedicated directory defined in the batch server parameters. This type of submission can be globally deactivated or reserved for certain users as a function of the value of the user setup EXTBATCH attached to the SUP group. The detail of the functioning of this type of submission can be found in the technical annex, which can also be executed by means of an automatic operation.
Detailed operation
The structures below describe the batch server functioning cycle. The diamonds figure in the logical tests, the yellow boxes are the simple actions, the green boxes the more complex actions described in another structure. The title of each structure is given in the blue box. Finally the red boxes indicate the terminating action.
The server is an ADONIX process functioning in a dedicated SERVX3 folder. It uses a group of tables that are found in the supervisor folder (and because of this are visible to all the folders). A single process server runs at any given moment. The launch of the batch server is made according to the following process :
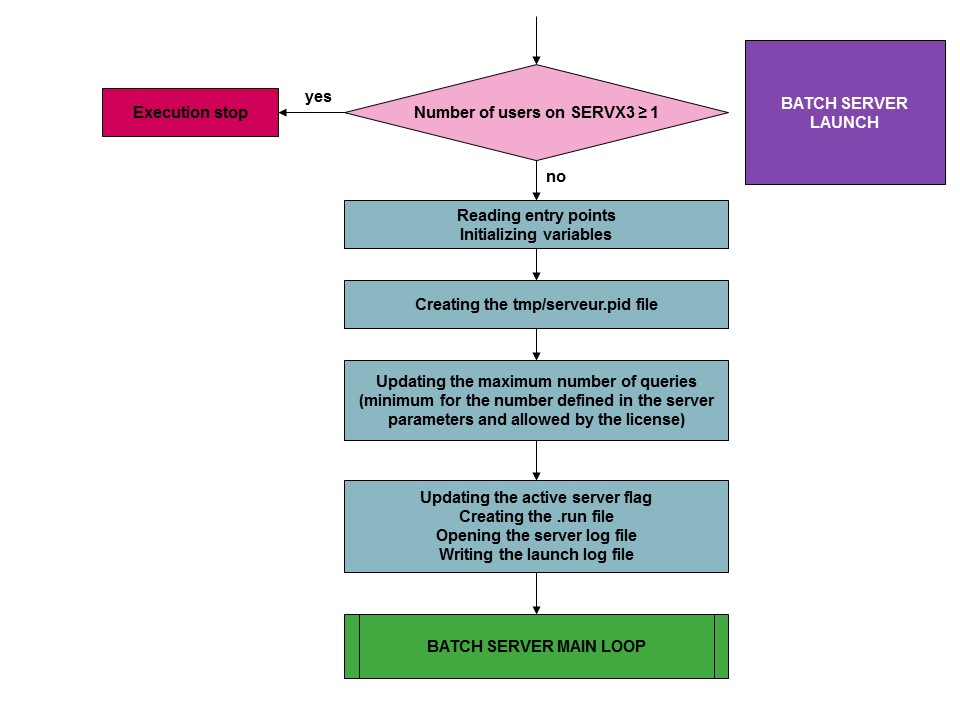
Once the verifications are carried out and the initializations made, the following files are set-up in the sub-directories of the SERVX3 directory:
- a run file is set-up in the FIL sub-directory. This file is not sufficient to determine that the server is active (the task having been suddenly interrupted). A polling technique is setup to verify that the server is still running. On the other hand, the fact that the run file is not there indicates that the server is not functioning.
- a server.pid file, giving the server process number, is created in the tmp directory.
- The server log is opened in the TRA directory of the folder.
In addition, the number of requests that can be simultaneously launched is verified, as defined in the batch server parameters.
The principle cycle for the functioning of the batch server is summarized below :
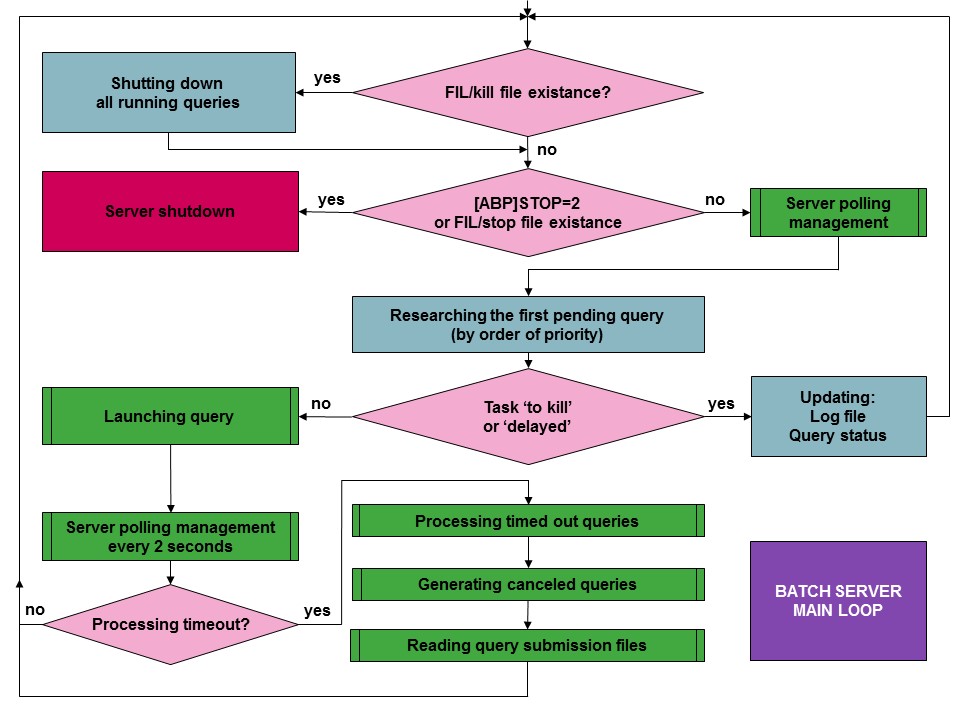
It should be noted that the presence of a kill file in the FIL directory of the SERVX3 folder leads to the stopping of the batch task that are currently running, and the presence of a stop file in the same directory leads to the server stopping. If the batch server is to be stopped by stopping all the requests, it will be necessary to place these two files in the directory, starting with the first, but within a time delay of 2 seconds, in order that the server starts by stopping the tasks then stops.
the highest priority goes to the oldest, provided the admissible launch delay (defined in hours in the task record) is not exceeded. It should be noted that the time constraints also define a programmed launch time for task. See the chapter concerning the management of time constraints below.
It should be noted that a "processing" time delay is used to define a time for which the server will periodically activate the process for the new requests that arrive (a time of between 30 seconds an one minute is usually sufficient, remembering that every 2 seconds a polling process is executed responding to the calls from the processes that interrogate the server to check that it is still active.
The launch of a request is made as shown in the diagram below :

In the SERVX3 folder, an ADONIX process is launched in the correct folder and the process number is recovered to update the corresponding information. If the request has been submitted by file, the corresponding files are updated.
In the target folder, the process execution associated with the request starts by opening the log file, verifies the execution constraints (single user mode, the does the user still have the execution rights ?). Then the process or script is launched and the end of task process is executed :
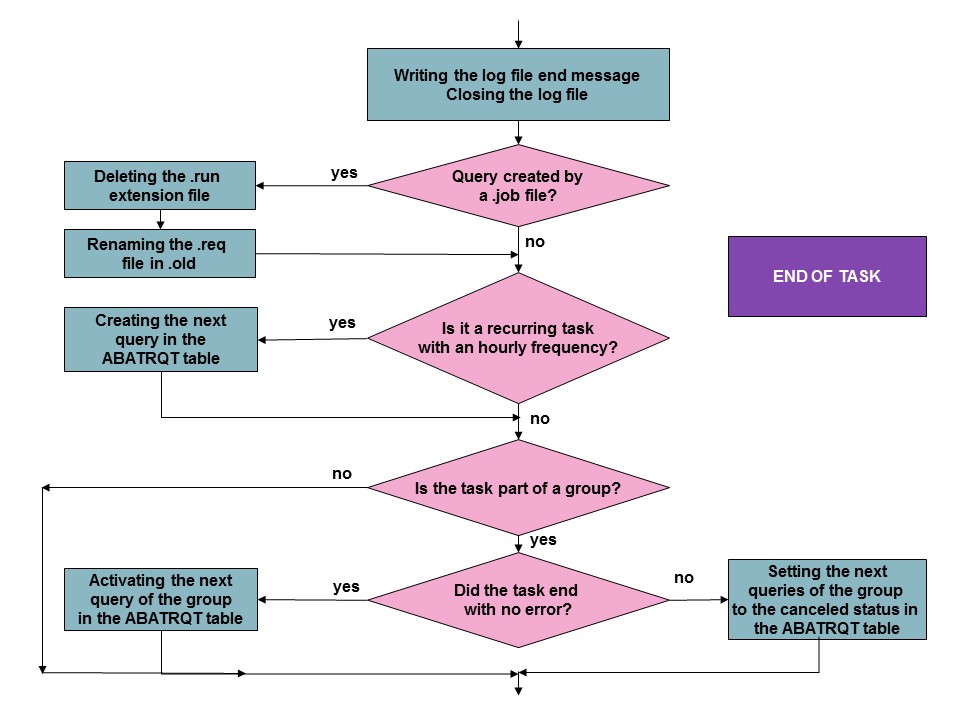
It should be noted that other than the opening of the log file and the updating of the files linked to the launch by file, the end of task activates the next task in a group if there have not been any errors, if not the next tasks have their status set to aborted.
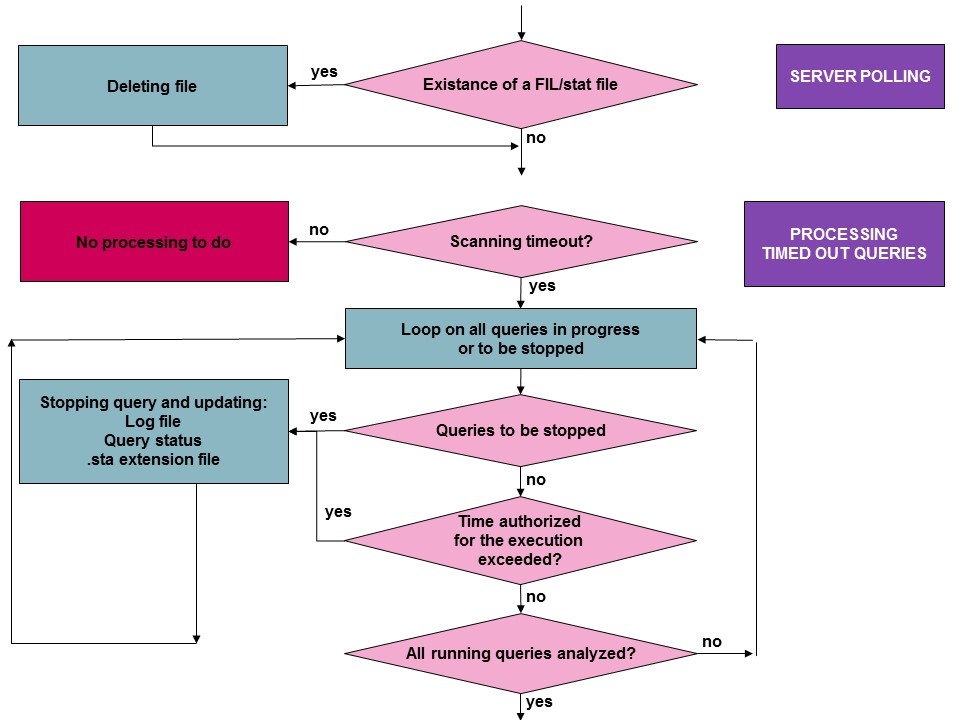
The additional process not described above concern firstly the polling (the stat file is deleted in the FIL directory in the SERVX3 folder, if it has been created by a task that tests the server is still active), and the processing of the requests with time-out. It should be noted that a delay that is greater than the first processing delay can be defined to avoid the test on request tests to verify if they have exceeded the given delay. For example, this process being very heavy, a delay in the order of 5 minutes can be proposed (this supposes that it is acceptable to exceed by more than 5 minutes the maximum authorized delay for this task) :
The update of the request list can be made using external files (this is the Read the request submission files box shown in the principal server section). This process is described in the diagram below :
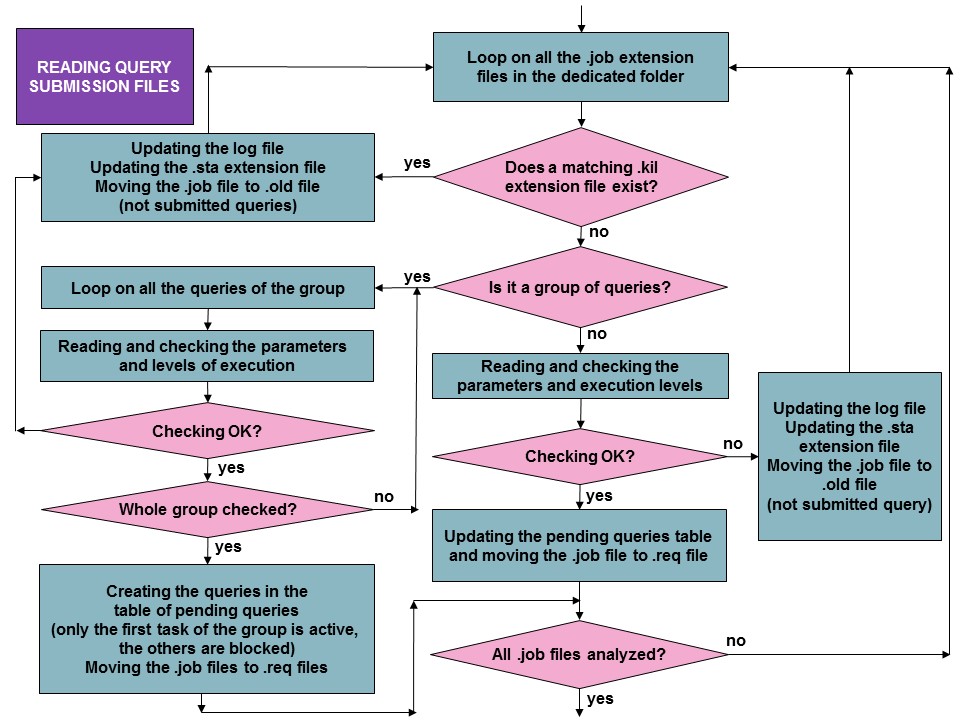
Finally, the last process present in the server execution cycle concerns the processing of recurring tasks. This is described below :

Management of time constraints
It is possible to define the time constraints for the launching of a task or group of tasks. These constraints are considered unique for the launch of the task. For instance:
- a task that can only be executed between 18:00 to 22:00 cannot be launched for execution at 17:00 (18:00 must be defined as the launch time).
- however, if following the execution of other delayed tasks as as a fact of the limited number of simultaneous tasks, the batch server is not in a position to launch the task until 22:20, it will be launched, except if it has been indicated that a delay greater than 4 hours will prevent the launch of the task in question.
- similarly, it is possible to indicate a task execution time-out: this time-out delay refers to the effective launch time of the task: it is used to limit the effective duration of the execution.
- thus, if the previous task must imperatively be terminated at 22:00, and it will not take more than one hour to execute, a maximum of 3 hours delay and 1 hour of timeout will be acceptable. If this task is programmed at 18:00, it will be terminated at 22:00 or it will have been interrupted or never launched.
The time constraints are defined by a dedicated table common to all the folders, and that are used to define the working days and the different times for the bank holidays etc. A time constrain code can be assigned to a task or to a group of tasks. It is important to note the following rules :
- the control of the time contraint for the task launched directly (by request file or by direct submission) is made as a function of the time constraint code assigned to it: the task can only be launch at the first possible time if the day allows it.
- if a task belongs to a group, the individual time constraints are not tested only that of the group (the group is launched conforming to the time constraint assigned to it, the tasks that it contains are then launched successively following on the successful completion of the previous task with no other time constraint control).
- if a task (or group of tasks) is triggered from a recurring task, the only constraint verified is the constraint linked to the exclusion calendars. In fact, in this case, an execution time (or frequency) is given directly in the recurring task and no other time constraint control is made in the task or group of tasks that are contained in the recurring task.
Tables used
It should be noted that the tables concerned are all located in the supervisor folder and this folder can take various names according to the product installed : for example X3, PAYE, GX. They are therefore common to all the folders.
Table | Table Title |
ABATABT [ABA] | Batch server (recurring tasks) - header |
ABATABTD [ABD] | Batch server (recurring tasks) - header |
ABATCAL [ABC] | Exclusion calendar |
ABATGRP [ABG] | Batch server (groups) |
ABATHOR [ABH] | Time constraints |
ABATPAR [ABP] | Batch server parameters |
ABATRQT [ABR] | Requests for the batch server |
ABATTAC [ABT] | Batch server (tasks) |